This demo introduces RealSinger, which can generate ultra-realistic singing voice with given music scores as input. The music score contains lyrics, notes and duration.
Synthesizing high-quality singing voices from music scores is a challenging problem in music generation and has many practical applications. Samples generated by existing singing voice synthesis (SVS) systems can roughly reflect the lyrics, pitch and duration in a given score, but they fail to contain necessary details. In this paper, based on stochastic differential equations (SDE) we propose RealSinger to generate 22.05kHz ultra-realistic singing voice conditioned on a music score. Our RealSinger learns to find the stochastic process path from a source of white noise to the target singing voice manifold under the conditional music score, allowing to sing the music score while maintaining the local voice details of the target singer. During training, our model learns to accurately predict the direction of movement in the ambient Euclidean space onto the low-dimensional singing voice manifold. RealSinger's framework is very flexible. It can either generate intermediate feature representations of the singing voice, such as mel-spectrogram, or directly generate the final waveform, as in the end-to-end style which rectifies defects and accumulation errors introduced by two-stage connected singing synthesis systems. An extensive subjective and objective test on benchmark datasets shows significant gains in perceptual quality using RealSinger. The mean-opinion-scores (MOS) obtained with RealSinger are closer to those of the human singer's original high-fidelity singing voice than to those obtained with any state-of-the-art method.
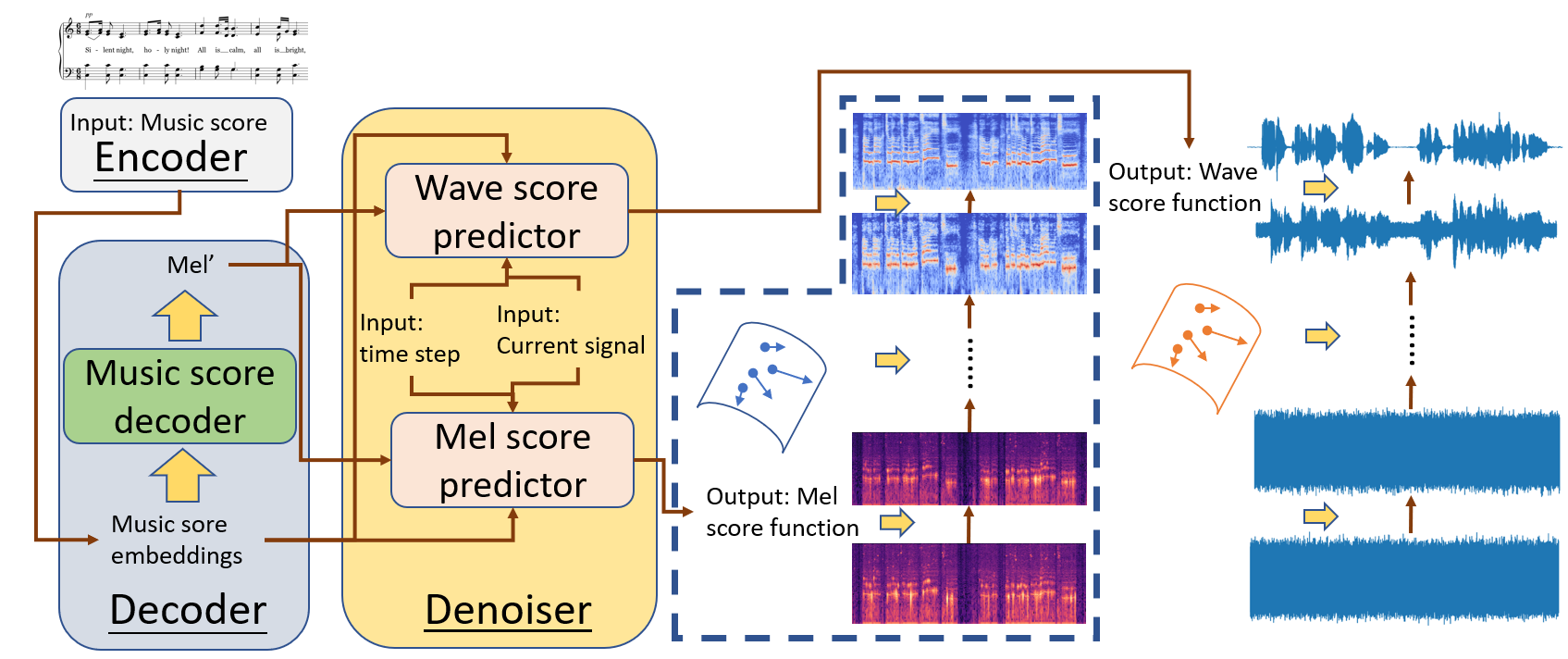
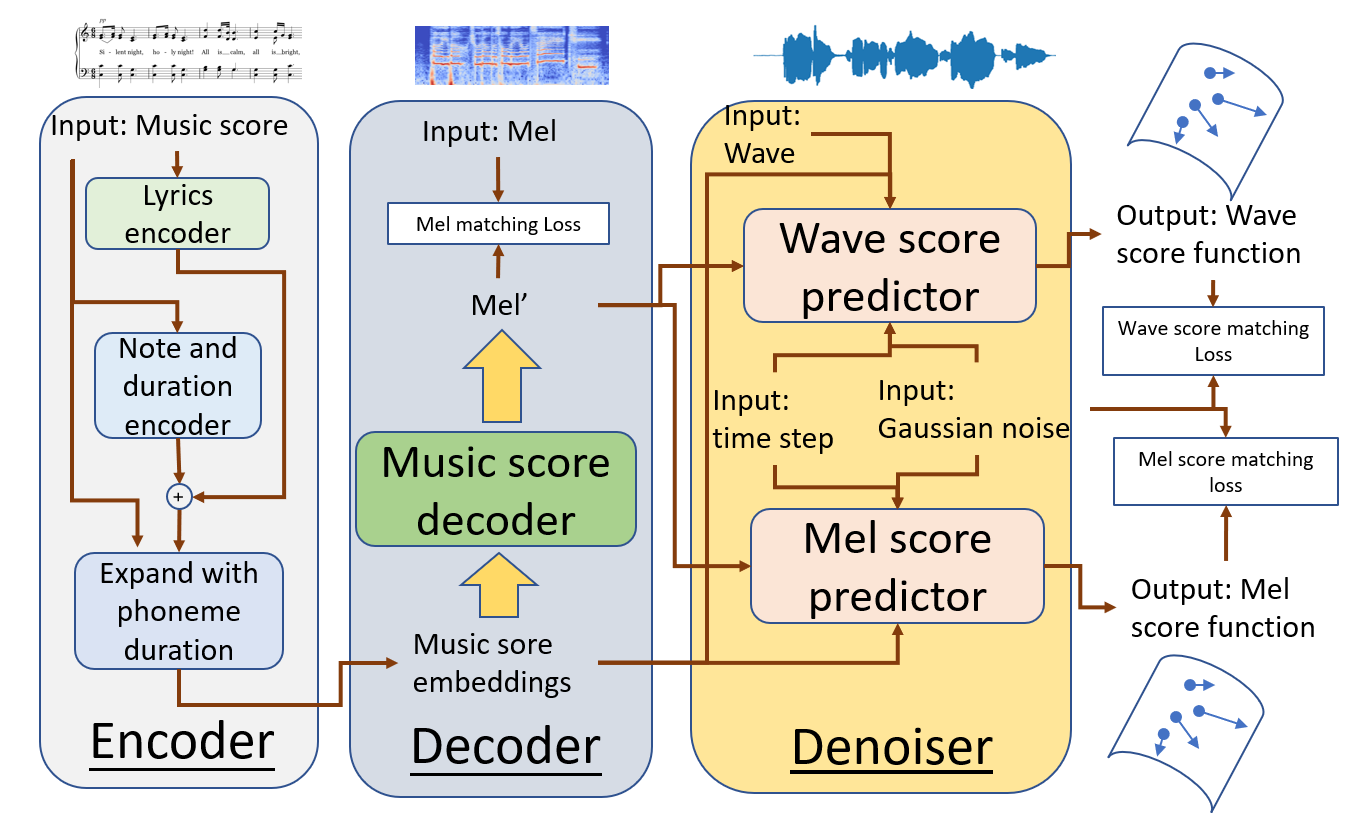
Frameworks and algorithms in RealSinger
The training pipeline of RealSinger.
The inference pipeline of RealSinger.